
728x90
반응형
✅ 스크래핑할 사이트
https://evs.nci.nih.gov/ftp1/CDISC/SDTM/SDTM%20Terminology.html
CDISC SDTM Controlled Terminology
evs.nci.nih.gov
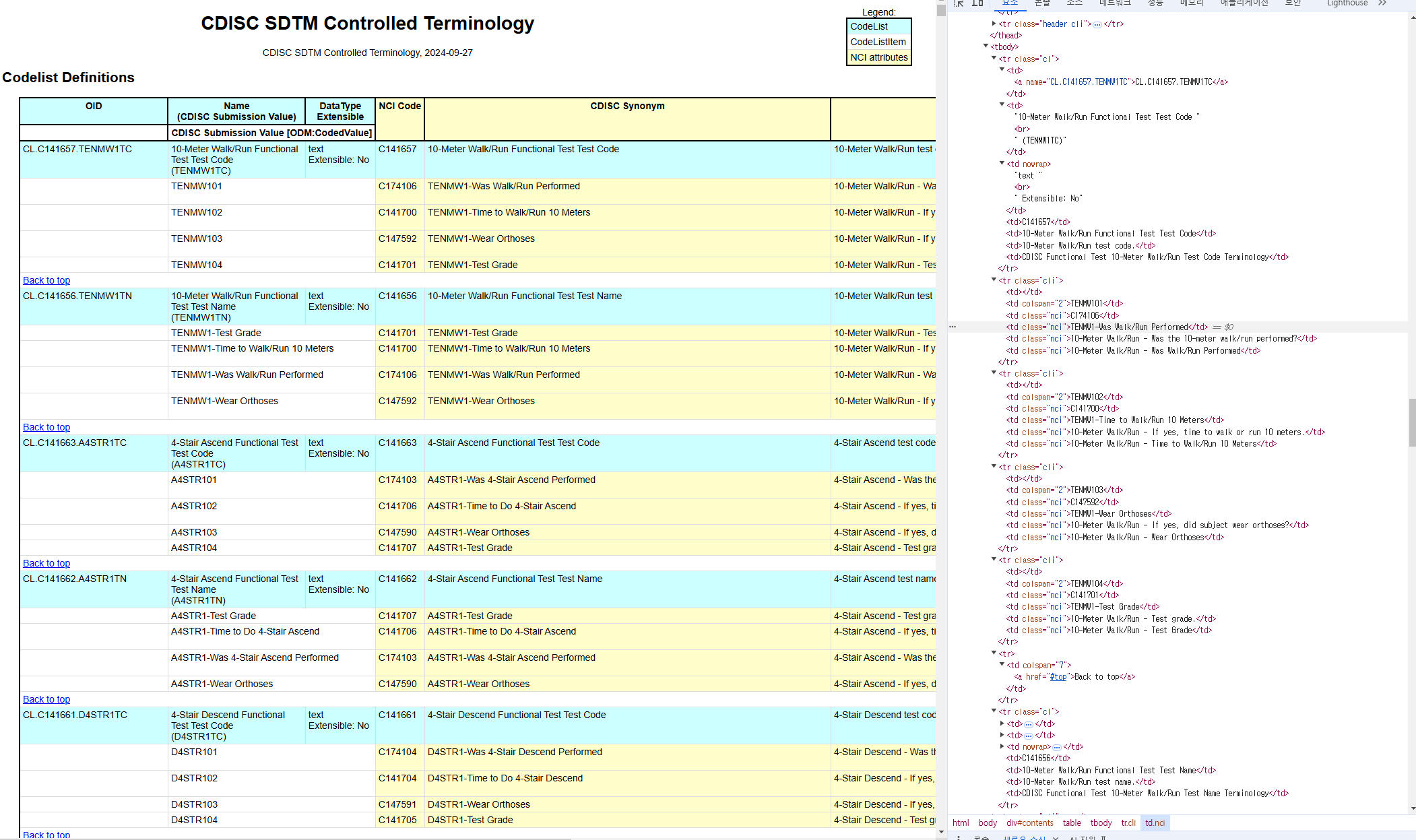
✅ 에러내용
위에 첨부한 사진과 같이 상위 데이터(파란색)이랑 하위 데이터(하얀색)을 나눠서 저장을 했다.
상위 데이터는 'cl'로 묶여 있었고, 하위 데이터는 'cli' 안에 묶여 있었다.
근데 하위 데이터 내용을 저장할 컬럼을 지정을 해도 상위 데이터와 같은 형식으로 저장 되어서 한 칸 씩 밀린다....
결국 에러를 해결하지 못하고 python으로 전처리를 해줬다 (컬럼 이동 등) ㅋㅋ
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 대상 URL
url = "https://evs.nci.nih.gov/ftp1/CDISC/SDTM/SDTM%20Terminology.html"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# <tbody> 태그
tbody = soup.find('tbody')
data = []
# 모든 <tr> 태그
rows = tbody.find_all('tr')
current_oid = None # 현재 OID
current_group = {} # 상위 데이터(파란색) 저장
group_data = [] # 하위 데이터(하얀색?) 저장
for row in rows: # 상위 데이터(파란색) 저장
if 'class' in row.attrs and 'cl' in row.attrs['class']:
if current_oid and group_data:
for g in group_data:
data.append({**current_group, **g})
group_data = []
cells = row.find_all('td')
current_oid = cells[0].text.strip()
current_group = {
"OID": current_oid,
"Name": cells[1].text.strip(),
"Data Type": cells[2].text.strip(),
"NCI Code": cells[3].text.strip(),
"CDISC Synonym": cells[4].text.strip(),
"CDISC Definition": cells[5].text.strip(),
"Preferred Term": cells[6].text.strip(),
}
data.append(current_group)
elif 'class' in row.attrs and 'cli' in row.attrs['class']: # 하위 데이터(하얀색?) 저장
cells = row.find_all('td')
name = ""
nci_code = ""
cdisc_synonym = ""
cdisc_definition = ""
preferred_term = ""
# 첫 번째 <td colspan="2"> 처리
if len(cells) >= 1 and 'colspan' in cells[0].attrs and cells[0]['colspan'] == "2":
name = cells[0].text.strip()
# 나머지 <td class="nci"> 처리
if len(cells) > 1:
nci_code = cells[1].text.strip()
if len(cells) > 2:
cdisc_synonym = cells[2].text.strip()
if len(cells) > 3:
cdisc_definition = cells[3].text.strip()
if len(cells) > 4:
preferred_term = cells[4].text.strip()
group_data.append({
"OID": current_oid,
"Name": name,
"Data Type": "", # Data Type 공백
"NCI Code": nci_code,
"CDISC Synonym": cdisc_synonym,
"CDISC Definition": cdisc_definition,
"Preferred Term": preferred_term,
})
elif row.find('a', href="#top"): # Back to top
if current_oid and group_data:
for g in group_data:
data.append({**current_group, **g})
group_data = []
df = pd.DataFrame(data)
해결 조언 부탁드립니당
728x90
반응형
'기타 > Error' 카테고리의 다른 글
| [Solved] RuntimeError: CUDA error: device-side assert triggered (1) | 2024.09.30 |
|---|
728x90
반응형
✅ 스크래핑할 사이트
https://evs.nci.nih.gov/ftp1/CDISC/SDTM/SDTM%20Terminology.html
CDISC SDTM Controlled Terminology
evs.nci.nih.gov
✅ 에러내용
위에 첨부한 사진과 같이 상위 데이터(파란색)이랑 하위 데이터(하얀색)을 나눠서 저장을 했다.
상위 데이터는 'cl'로 묶여 있었고, 하위 데이터는 'cli' 안에 묶여 있었다.
근데 하위 데이터 내용을 저장할 컬럼을 지정을 해도 상위 데이터와 같은 형식으로 저장 되어서 한 칸 씩 밀린다....
결국 에러를 해결하지 못하고 python으로 전처리를 해줬다 (컬럼 이동 등) ㅋㅋ
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 대상 URL
url = "https://evs.nci.nih.gov/ftp1/CDISC/SDTM/SDTM%20Terminology.html"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# <tbody> 태그
tbody = soup.find('tbody')
data = []
# 모든 <tr> 태그
rows = tbody.find_all('tr')
current_oid = None # 현재 OID
current_group = {} # 상위 데이터(파란색) 저장
group_data = [] # 하위 데이터(하얀색?) 저장
for row in rows: # 상위 데이터(파란색) 저장
if 'class' in row.attrs and 'cl' in row.attrs['class']:
if current_oid and group_data:
for g in group_data:
data.append({**current_group, **g})
group_data = []
cells = row.find_all('td')
current_oid = cells[0].text.strip()
current_group = {
"OID": current_oid,
"Name": cells[1].text.strip(),
"Data Type": cells[2].text.strip(),
"NCI Code": cells[3].text.strip(),
"CDISC Synonym": cells[4].text.strip(),
"CDISC Definition": cells[5].text.strip(),
"Preferred Term": cells[6].text.strip(),
}
data.append(current_group)
elif 'class' in row.attrs and 'cli' in row.attrs['class']: # 하위 데이터(하얀색?) 저장
cells = row.find_all('td')
name = ""
nci_code = ""
cdisc_synonym = ""
cdisc_definition = ""
preferred_term = ""
# 첫 번째 <td colspan="2"> 처리
if len(cells) >= 1 and 'colspan' in cells[0].attrs and cells[0]['colspan'] == "2":
name = cells[0].text.strip()
# 나머지 <td class="nci"> 처리
if len(cells) > 1:
nci_code = cells[1].text.strip()
if len(cells) > 2:
cdisc_synonym = cells[2].text.strip()
if len(cells) > 3:
cdisc_definition = cells[3].text.strip()
if len(cells) > 4:
preferred_term = cells[4].text.strip()
group_data.append({
"OID": current_oid,
"Name": name,
"Data Type": "", # Data Type 공백
"NCI Code": nci_code,
"CDISC Synonym": cdisc_synonym,
"CDISC Definition": cdisc_definition,
"Preferred Term": preferred_term,
})
elif row.find('a', href="#top"): # Back to top
if current_oid and group_data:
for g in group_data:
data.append({**current_group, **g})
group_data = []
df = pd.DataFrame(data)
해결 조언 부탁드립니당
728x90
반응형
'기타 > Error' 카테고리의 다른 글
| [Solved] RuntimeError: CUDA error: device-side assert triggered (1) | 2024.09.30 |
|---|