
이번 MLOps 프로젝트에 MLflow를 사용하여 모델 관리 등등을 진행하기로 했다.
error, 막혔던 부분 등을 잊어버리지 않고 다음에 mlflow 사용할 일이 있다면 이때 시행착오를 줄이기 위해 작성하는 글로...
우당탕탕 시행착오기 시작합니다.
✅ MLFlow란?
머신러닝의 생애주기를 위한 오픈 소스 플랫폼이다.
MLflow의 전체 흐름을 잘 나타내는 그림이다.
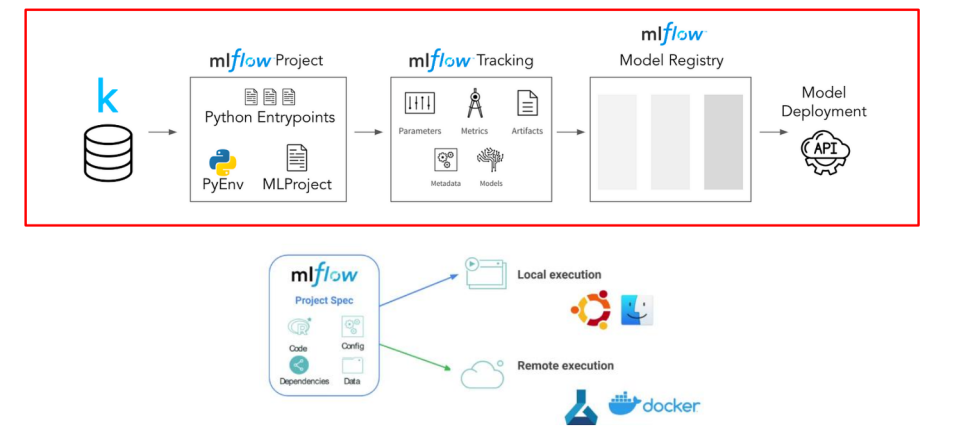
근데 난 이 그림이 더 이해하기 쉬웠다..ㅎㅎ
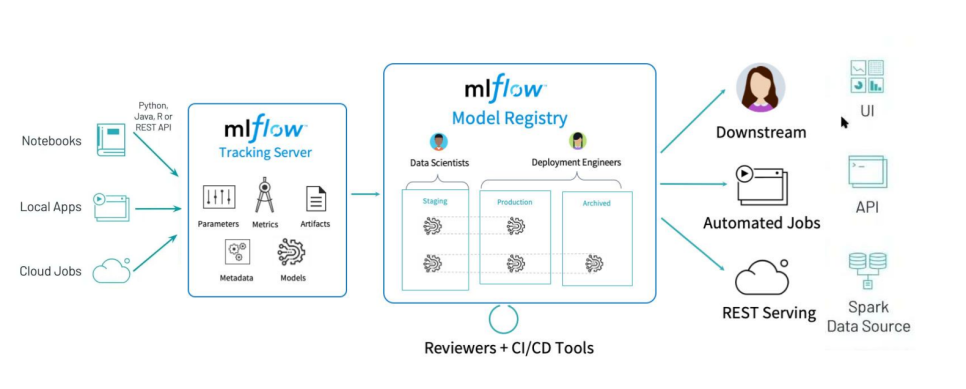
- 주요 구성요소
1) MLflow Tracking: 실험 기록을 추적하며, 파라미터와 그 결과를 비교 및 기록한다.
- 예를 들어, 여러 사람이 하나의 MLflow 서버위에서 각자 자기 실험을 만들고 공유할 수 있다.
- 각 실행에 사용한 소스 코드, 하이퍼 파라미터, Metric, 부산물(모델 Artifact, Chart Image)등을 저장할 수 있다.
2) MLflow Projects: ML code를 재사용, 재구현 가능한 형태로 패키징하여 다른 데이터 과학자들과 공유하거나 프로덕션으로 변환한다. MLflow Tracking API를 사용하면 MLflow는 프로젝트 버전을 모든 파라미터와 자동으로 로깅할 수 있다.
- 학습 된 모델, 파라미터, 성능평가지표 등을 기록한 정보와 저장된 모델을 불러올 수 있다.
- 학습한 모델 정보들이 어떤 구조를 가지는지 볼 수 있다.
ex) conda 환경세팅 정보, requirement 텍스트 파일(패키지 세팅 정보), 학습 모델 등등
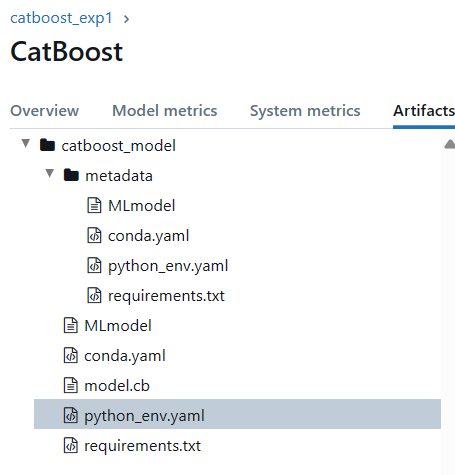
3) MLflow Models: 다양한 ML 라이브러리로 만들어진 모델을 관리하고 다양한 모델 서빙과 추론 플랫폼으로 배포한다. 즉, 모델은 모델파일과 코드로 저장할 수 있고 이를 AWS, GCP 등 다양한 플랫폼에 배포할 수 있는 여러 도구를 제공한다.
4) MLflow Registry: 중앙 모델 저장를 제공함으로써, 한 MLflow 모델의 전체 라이프 사이클을 협동적으로 관리한다.. 이러한 관리 작업에는 모델 버전 관리(versioning), 모델 스테이지 관리(stage transitions), 주석 처리등을 포함한다.
- MLflow로 실행한 머신러닝 모델을 Model Registry(모델 저장소)에 등록할 수 있다.
- 모델 저장소에 모델이 저장될 때마다 해당 모델에 버전이 자동으로 올라간다.
- Model Registry에 등록된 모델은 다른 사람들에게 쉽게 공유 가능하고, 쉽게 활용할 수 있다.
- 파라미터, 배치사이즈, 에포크, 모델 경량화 유무 등을 기록하여 이전 실험의 모델들과 비교가 쉬워짐
++) 어떤 블로그에서 요리를 MLflow랑 비교해서 설명해준 글을 봤는데 이해하기 쉬워서 공유
- 집에서 요리만들때, 레시피를 기록해야 어떤 조합이 좋은지 알 수 있음(파라미터, 모델 구조 등) => mlflow
- 여러 시행착오를 겪으며 요리함(머신러닝 모델링도 많은 실험을 함!) => mlflow
- 이 레시피에서 제일 맛있었던(성능이 좋았던)레시피를 레스토랑에 사용한다 => mlflow
- 요리 만드는 과정에서 생기는 부산물 저장!(=모델 Artifact, 이미지 등) => mlflow
- 예를 들어, 타코(모델)는 다양한 종류가 있으므로 언제 만든 타코인지(=모델 생성일), 얼마나 맛있었는지(모델 성능), 유통기한 등(=모델 메타 정보)을 기록해둘 수 있음 => mlflow
- 언제부터 닭고기 타코, 돼지고기 타코, 부리또를 만들어 판매(=여러 모델 운영) => mlflow
더 자세한 내용은 mlflow 홈페이지 및 아래 블로그 참고!!
도움을 많이 받았다.
MLflow 소개 및 Tutorial
머신러닝 라이프 사이클을 관리할 수 있는 오픈소스인 MLflow에 대한 소개 및 간단한 Tutorial에 대한 글입니다
zzsza.github.io
✅ 환경세팅
원래 로컬에서 MLFlow를 실행할 때는 "mlflow ui -p 1234"와 같은 명령어를 사용해서 주소를 받은 후, ui에 접속하면 된다.
그런데 팀 프로젝트 등에서는 다른 사람도 같은 mlflow 주소에 접속할 수 있도록 해주어야하니까, ip 주소와 포트 공개 설정해야한다.
이 공유된 주소로 이제 mlflow를 사용하는 법을 회고(?)하겠다.
시행착오와 여러 선택이 포함되어 있당.
- Visual Studio에서 작업 or Jupyter notebook에서 작업?


데이터 탐색, 전처리, 여러 모델링 등등 데이터를 다루고 결과를 바로 보고 싶으면 Jupyter를 쓰는게 맞을 것 같았다. 그런데 이미 전처리 끝내고 모델링 단계를 진행 중이며, web으로 배포 준비까지 연결되어 있는 프로젝트이므로 visual studio를 사용했다.
(만약, 다른 ops 프로젝트를 수행한다면 지금처럼 초기 데이터 탐색, 전처리, 시각화, 로컬 모델링 기본 실험 등은 주피터나 colab으로 하고 이후 단계로 넘어와서는 visual studio를 사용할 것이다)
- 아나콘다 프롬프트 명령어 알아보기
cd <디렉토리> : 디렉토리 이동
cd.. : 이전 디렉토리로 이동
cls : 화면 클리어
dir : 현재 디렉토리의 폴더/파일 리스트
del <파일/폴더명> : 파일/폴더 삭제
mkdir <폴더명> : 폴더 생성
드라이브명: : 드라이브간 이동은 ex) c: , d: 처럼 드라이브명:으로 사용
ls : 현재 폴더의 파일/폴더 리스트
skhynix_mlops_mlflow라는 작업환경을 생성해주었다.
- 가상환경 생성
- 생성 이유
1) 프로젝트 의존성 분리 및 충돌 방지
2) 환경 재현성 : 프로젝트 환경을 requirements.txt나 environment.yml로 기록해서 다른 시스템이나 팀원들이 동일 환경을 재현할 수 있도록 하려고
3) 시스템 안정성 유지
- anaconda 사용 vs venv 사용

--> 정리해보면, anaconda는 많은 패키지나 시스템 등을 담은 포괄적인 도구이지만 공간을 많이 차지하고 설치 및 관리가 복잡하다. venv는 경량이고 anconda보다 간단하지만, 필요한 패키지를 직접 설치하고 관리하는 번거로움이 있다...정도이다.
컴퓨터 용량도 넉넉하고 패키지 직접 설치하기 귀찮아서 anaconda를 사용했다.
- 실제 작업 내용
1) 가상환경 생성 및 활성화
--> python 3.11을 사용했는데, 이게 내가 필요한 패키지들이 다 설치되어 있는지 걱정되어서 패키지 테스트도 수행하였다.
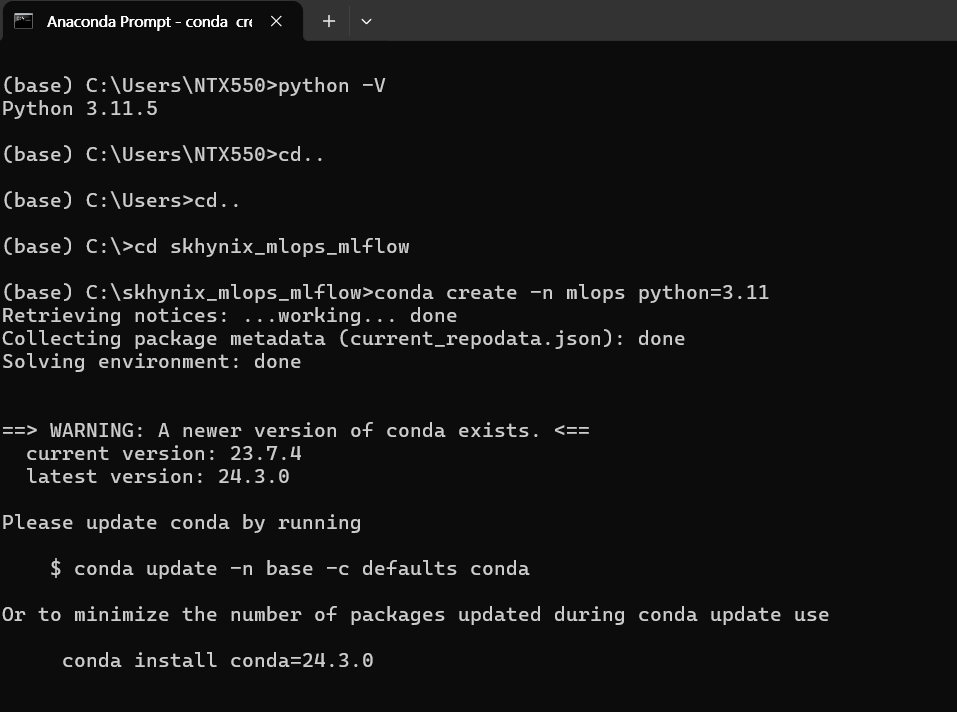
cd C:\skhynix_mlops_mlflow
conda create -n mlops python=3.8
conda activate mlops
2) 필수 패키지 설치
xgboost, catboost, mlflow, lstm, cnn-lstm 모델 등을 사용할 예정이라 관련된 패키지들을 모두 설치해주었다.
conda install -c conda-forge mlflow
conda install -c conda-forge catboost
conda install -c conda-forge xgboost
conda install scikit-learn
conda install tensorflow
conda install pandas numpy matplotlibpip install mlflow을 사용하는 방법도 있다고 하는데..나는 conda로 설치해주었다.
오래걸렸다. 특히 mlflow가 오래걸림 당황하지 말자! 인내심을 갖자!
3) 설치된 패키지 테스트
import mlflow
import catboost
import xgboost
import tensorflow as tf
import sklearn
print("All packages are installed and working.")
여기서 고생 좀 했다...계속 import가 안되길래..열심히 서치했더니 python 인터프리터에서 실행해보라는 조언을 봤고, 그랬더니 됐다!!!
(mlops) C:\skhynix_mlops_mlflow>python
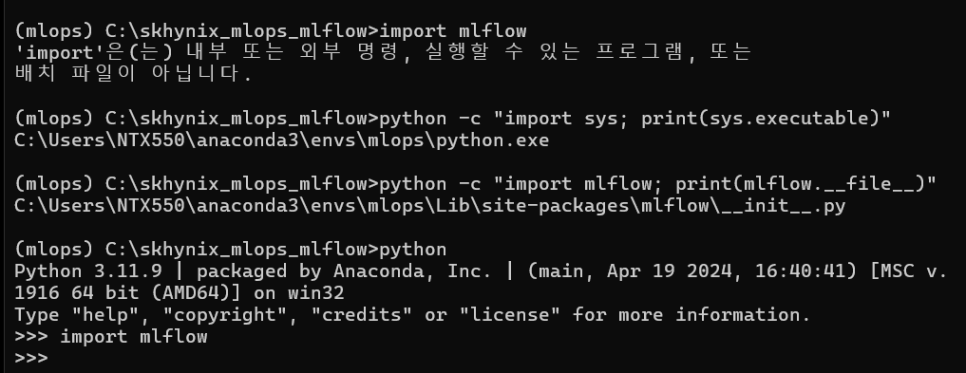
그리고 tensorflow는 설치가 계속 conda로 되지 않아서, pip install 명령어를 사용했다
(혼용하는거 비추하지만 어쩔 수 없었음ㅜㅜ)
4) 기본 기능 테스트
# TensorFlow를 사용한 간단한 모델 테스트
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation='relu', input_shape=(10,)),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam', loss='mean_squared_error')
print("TensorFlow 설치 성공적.")
# CatBoost 모델 테스트
from catboost import CatBoostRegressor
model = CatBoostRegressor(iterations=10, depth=2, learning_rate=1, loss_function='RMSE')
print("CatBoost 설치 성공적.")# TensorFlow 모델을 가상 데이터로 훈련
import numpy as np
X_fake = np.random.rand(100, 10)
y_fake = np.random.rand(100, 1)
model.fit(X_fake, y_fake, epochs=5)
print("TensorFlow model trained on fake data successfully.")
# CatBoost 모델을 가상 데이터로 훈련
model.fit(X_fake, y_fake)
print("CatBoost model trained on fake data successfully.")import mlflow
# MLflow 실험 시작
with mlflow.start_run():
mlflow.log_param("test_param", 5)
mlflow.log_metric("test_metric", 0.85)
print("Logged to MLflow successfully.")
5) mlflow 설정
(mlops) C:\skhynix_mlops_mlflow>python
>>> import mlflow
>>> mlflow.set_tracking_uri("http://공유 mlflow 주소")anaconda prompt에서 가상 환경(나는 mlops라고 명명함)을 구축하고 필요한 패키지 설치를 마쳤다. 이제, 개발환경인 visual studio code에서 모델링 작업을 할 것이다.
✅ 모델 학습
이제 visual studio code에서 모델링을 해보는 시간~
- Python 인터프리터 및 가상 환경 선택
ctrl+shift+P을 눌러서 select interpreter 누르면, 사용 가능한 인터프리터 목록이 나타난다.
나는 mlops 가상환경을 만들어주었기 때문에 'mlops'의 파이썬을 클릭하였다. (anaconda python 아님!!)
- 가상환경 활성화
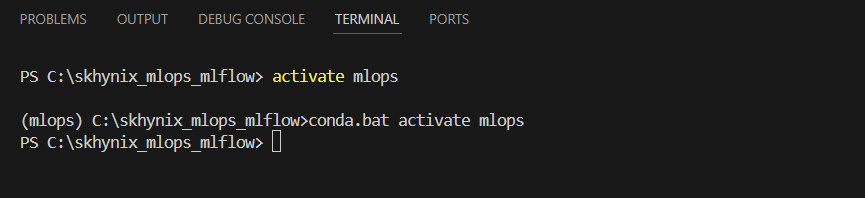
- (실습용) CatBoost 모델 훈련 및 MLflow로 로깅
.ipynb 노트북 파일이 아닌 .py 스크립트를 사용했다.
그리고 다양한 모델을 사용(RF, LSTM 등)할건데, 일단은 Catboost 모델로 실습을 진행했다.
- 주요 코드 예시
# MLFlow uri 설정
mlflow.set_tracking_uri("Mlflow 주소 작성하기")
# 실험명 설정 : 나는 catboost의 1번 실험이라는 의미로 이 이름을 명명함
mlflow.set_experiment("catboost_exp1")# 기본적인 코드
# CatBoost 모델 훈련 및 로깅
with mlflow.start_run(run_name='CatBoost') as run:
catboost_model = CatBoostRegressor(iterations=500, depth=4, learning_rate=0.1, loss_function='MAE', verbose=100)
catboost_model.fit(X_train, y_train, eval_set=(X_test, y_test), plot=False)
# 평가
y_pred_train = catboost_model.predict(X_train)
y_pred_test = catboost_model.predict(X_test)
train_mae = mean_absolute_error(y_train, y_pred_train)
train_mse = mean_squared_error(y_train, y_pred_train)
train_r2 = r2_score(y_train, y_pred_train)
test_mae = mean_absolute_error(y_test, y_pred_test)
test_mse = mean_squared_error(y_test, y_pred_test)
test_r2 = r2_score(y_test, y_pred_test)
# 로깅: 파라미터
mlflow.log_params({
"iterations": 500,
"depth": 4,
"learning_rate": 0.1,
"loss_function": 'MAE'
})
# 로깅: 메트릭
mlflow.log_metrics({
"train_mae": train_mae,
"train_mse": train_mse,
"train_r2": train_r2,
"test_mae": test_mae,
"test_mse": test_mse,
"test_r2": test_r2
})
# 로깅: 모델
mlflow.catboost.log_model(catboost_model, "catboost_model")
성능이 너무 메롱이라 이것저것 만져보고 수정도 해볼 예정입니다.
그리고 아마 다음 게시물에 모델 등록 및 배포 과정이 있을?것?같습니다!!
제가 너무 빙빙 돌아가고 있거나, 더 효율적인 운영 방법이 있다!라고 느껴지신다면!! 아낌없는 조언부탁드립니다.
MLflow 너무 어려워요...배포도 공부해봐야하는데...
'AI & DATA > AI' 카테고리의 다른 글
| Google의 Titans: 인간과 유사한 기억력을 갖춘 신경망의 탄생 (1) | 2025.02.05 |
|---|---|
| AI개발자가 준비하는 면접 기초 개념 (2) (0) | 2024.06.12 |
| AI개발자가 준비하는 면접 기초 개념 (1) (0) | 2024.05.29 |
| 딥러닝 프레임워크 비교 및 분석(Tensorflow / Keras / PyTorch) (0) | 2024.05.07 |