
728x90
반응형
✅ 역전파(Backpropagation) 알고리즘이란?
신경망의 가중치를 학습시키기 위한 방법으로, 출력에서부터 입력 방향으로 오차를 전파하여 각 층의 가중치를 업데이트합니다. 이를 통해 모델의 예측 오류를 최소화합니다. 주로 경사 하강법(Gradient Descent)과 함께 사용됩니다.
✅ 딥러닝에서 사용되는 활성화 함수의 종류와 특징
- 시그모이드 함수 (Sigmoid Function)
- 특징: 출력 값을 0과 1 사이로 압축합니다.
- 장점: 출력 값이 확률로 해석될 수 있어 이진 분류 문제에 유용합니다.
- 단점: 경사가 작아질 수 있는 Vanishing Gradient 문제가 발생할 수 있습니다.
- 하이퍼볼릭 탄젠트 (tanh) 함수
- 특징: 출력 값을 -1과 1 사이로 압축합니다.
- 장점: 시그모이드 함수보다 중심이 0에 가까워서 경사 소실 문제가 완화됩니다.
- 단점: 여전히 Vanishing Gradient 문제를 완전히 해결하지는 못합니다.
- 렐루 (ReLU: Rectified Linear Unit) 함수
- 특징: 음수 입력에 대해서는 0을 출력하고, 양수 입력에 대해서는 입력 값을 그대로 출력합니다.
- 장점: 계산이 간단하고, Vanishing Gradient 문제를 완화합니다.
- 단점: 음수 입력에 대해서는 학습이 이루어지지 않는 Dying ReLU 문제가 발생할 수 있습니다. ReLU의 출력이 음수인 경우 그 입력에 대해 기울기가 0이 되어버립니다. 이렇게 되면 해당 뉴런은 더 이상 학습되지 않습니다. 이는 특히 초기화나 학습률이 잘못 설정된 경우 발생할 수 있습니다. 또한, 매우 큰 양수 입력에 대해서는 출력 값도 매우 커질 수 있습니다. 이는 신경망의 상위 계층에서 기울기를 폭발시키는 문제를 일으킬 수 있습니다.
- 리키 렐루 (Leaky ReLU) 함수
- 특징: 음수 입력에 대해 작은 기울기를 가집니다 (e.g., f(x)=0.01xf(x) = 0.01x for x<0x < 0).
- 장점: Dying ReLU 문제를 완화합니다.
- 단점: 하이퍼파라미터를 추가로 조정해야 할 수 있습니다.
- 스위시 (Swish) 함수
- 특징: f(x)=x⋅sigmoid(βx)f(x) = x \cdot sigmoid(\beta x)
- 장점: ReLU보다 성능이 더 좋다고 알려져 있습니다.
- 단점: 계산이 다소 복잡합니다.
✅ Sigmoid 대신 ReLU를 많이 쓰는 이유
- Vanishing Gradient 문제 완화: ReLU는 활성화 함수의 출력이 0 이상으로 유지되기 때문에 경사 소실 문제가 완화됩니다.
- 계산 효율성: ReLU는 계산이 간단하여 학습 속도가 빨라집니다.
- 희소성: ReLU는 일부 뉴런을 비활성화하여 희소성을 가지게 되고, 이는 과적합을 방지하는 데 도움이 됩니다.
✅ 볼츠만 머신 (Boltzmann Machine)이란?
가시층(Visible Layer)와 은닉층(Hidden Layer) 총 두 개의 층으로 신경망을 구성하는 방법으로, 모든 뉴런이 연결되어 있는 완전 그래프 형태이며, 제한된 볼츠만 머신(RBM)에서는 같은 층의 뉴런들은 연결되어 있지 않은 모양입니다.
- 특징: 에너지 기반 모델로, 각 상태의 확률은 에너지 함수에 따라 결정됩니다. 노드 간의 상호작용을 통해 학습하며, 샘플링 및 확률 분포를 추정하는 데 사용됩니다.
- 용도: 제한된 볼츠만 머신(RBM)은 추천 시스템, 차원 축소, 특성 학습 등에 사용됩니다.
✅ Weight Initialization이란?
- 제로 초기화 (Zero Initialization)
- 특징: 모든 가중치를 0으로 초기화.
- 단점: 비대칭성 문제로 인해 비효율적.
- 랜덤 초기화 (Random Initialization)
- 특징: 가중치를 무작위로 초기화.
- 장점: 비대칭성을 깨뜨릴 수 있음.
- 단점: 학습 속도에 영향을 미칠 수 있음.
- Xavier 초기화
- 특징: Var(W)=2in_nodes+out_nodes\text{Var}(W) = \frac{2}{\text{in\_nodes} + \text{out\_nodes}}
- 장점: 신경망이 너무 크거나 너무 작지 않도록 가중치를 초기화.
- 용도: 주로 시그모이드, tanh 함수와 함께 사용.
- He 초기화
- 특징: Var(W)=2in_nodes\text{Var}(W) = \frac{2}{\text{in\_nodes}}
- 장점: ReLU와 같은 활성화 함수에 적합.
- 용도: ReLU, Leaky ReLU 함수와 함께 사용.
✅ 뉴럴넷 단점 및 One-Shot Learning이란?
- 뉴럴넷의 단점:
- 데이터 의존성: 많은 양의 데이터가 필요합니다.
- 계산 비용: 높은 계산 자원이 필요합니다.
- 학습 시간: 학습에 많은 시간이 소요됩니다.
- One-Shot Learning:
- 정의: 극소량의 데이터로 학습하여 새로운 샘플을 인식할 수 있는 학습 방법.
- 특징: 메타러닝, 프로토타입 네트워크, 시암 신경망 등이 사용됩니다.
- 용도: 얼굴 인식, 객체 인식 등 소량의 데이터로 일반화가 필요한 문제에 사용됩니다.
✅ Gradient Descent란?
- 손실 함수를 최소화하기 위해 사용되는 최적화 알고리즘입니다. 각 반복에서 손실 함수의 기울기(gradient)를 계산하고, 그 방향으로 가중치를 업데이트합니다.
- 공식: θ=θ−η∇J(θ)
- 여기서 θ\theta는 가중치 파라미터, η\eta는 학습률, ∇J(θ)\nabla J(\theta)는 손실 함수 J(θ)J(\theta)의 기울기입니다.
- Gradient Descent 중에 Loss가 증가하는 이유:
- 큰 학습률로 인해 최소점으로 수렴하기보다는 최소점을 지나쳐 손실이 증가할 수 있습니다.
- 손실 함수가 매우 비선형이거나 복잡한 경우, 작은 기울기 변화에도 큰 손실 변화가 있을 수 있습니다.
- 미니 배치를 사용하면 특정 배치에서의 손실이 일시적으로 증가할 수 있습니다. 이는 데이터의 랜덤성에 기인합니다.
✅ Training 세트와 Test 세트를 분리하는 이유
- 모델 평가의 정확성: 모델이 학습된 데이터에 대해 잘 작동하는지 뿐만 아니라, 학습되지 않은 새로운 데이터에 대해서도 잘 작동하는지 확인해야 합니다. 이를 일반화 성능이라고 합니다.
- 과적합 방지: 모델이 학습 데이터에 과도하게 맞춰지면(과적합) 새로운 데이터에 대해 성능이 떨어질 수 있습니다. Test 세트는 이를 검증하는 역할을 합니다.
- Test 세트가 오염되었다는 말의 뜻:
- 데이터 누수: 학습 과정에서 Test 세트의 정보가 모델에 유출되는 경우. 예를 들어, Test 세트의 일부 데이터를 학습 과정에서 사용했거나, 특성 공학 과정에서 Test 세트의 통계 정보를 사용한 경우입니다.
- 사전노출: Test 세트가 이미 모델 학습이나 튜닝 과정에 사용되어 모델이 Test 세트에 특화되도록 조정된 경우입니다. 이는 모델의 일반화 성능을 왜곡시킵니다.
- 재사용: Test 세트를 반복적으로 사용하여 모델을 평가하고 튜닝하는 경우도 포함됩니다. 이는 Test 세트가 실제 새로운 데이터에 대한 성능을 제대로 평가하지 못하게 만듭니다.
✅ SGD, RMSprop, Adam란?
- SGD (Stochastic Gradient Descent):
- 정의: 확률적 경사 하강법으로, 전체 데이터 세트 대신 미니 배치 혹은 단일 샘플을 사용하여 기울기를 계산하고 가중치를 업데이트합니다.
- 특징: 계산 효율성이 높고, 더 빠르게 최적점에 도달할 수 있습니다. 하지만 진동이 크고 수렴이 느릴 수 있습니다.
- 공식: θ=θ−η∇J(θ)
- RMSprop (Root Mean Square Propagation):
- 정의: 각 가중치의 학습률을 적응적으로 조정하여 학습을 안정화하는 방법입니다.
- 특징: 학습률이 너무 크거나 작은 문제를 해결하여 빠르고 안정적인 수렴을 돕습니다.
- 공식
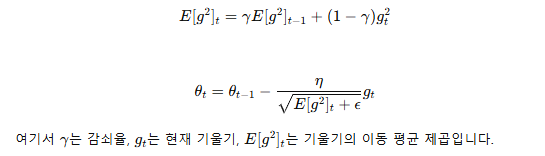
- Adam (Adaptive Moment Estimation):
- 정의: 모멘텀과 RMSprop을 결합한 최적화 알고리즘입니다.
- 특징: 빠르고 안정적인 수렴을 위해 1차 및 2차 모멘트를 모두 사용합니다.
- 공식

✅ 미니배치를 작게 할 때의 장단점
장점:
- 더 자주 업데이트: 더 빈번한 업데이트로 인해 더 빠른 학습과 보다 빠른 수렴을 가능하게 합니다.
- 노이즈에 대한 강인성: 더 많은 노이즈가 포함되어 있을 때 모델이 더 잘 일반화되도록 돕습니다.
- 메모리 효율성: 작은 미니배치는 메모리 사용을 줄일 수 있습니다.
단점:
- 진동 증가: 잦은 업데이트로 인해 손실 함수의 값이 진동할 수 있습니다.
- 효율성 저하: 각 업데이트마다 오버헤드가 발생하여 전체 학습 시간이 길어질 수 있습니다.
- 병렬 처리의 어려움: 너무 작은 배치는 GPU 및 병렬 처리의 효율성을 감소시킬 수 있습니다
✅ 딥러닝할 때 GPU를 쓰면 좋은 이유
- 병렬 처리 능력: GPU는 수천 개의 작은 코어를 가지고 있어, 대규모 행렬 연산 및 벡터 연산을 병렬로 처리할 수 있습니다. 이는 딥러닝에서 자주 사용되는 행렬 곱셈 및 합성곱 연산을 매우 빠르게 수행할 수 있게 합니다.
- 고속 연산: GPU는 대규모 데이터를 처리하는 데 매우 빠르며, 이는 모델 학습 속도를 크게 향상시킵니다.
- 메모리 대역폭: GPU는 높은 메모리 대역폭을 가지고 있어, 대규모 데이터 전송 속도가 빠릅니다. 이는 딥러닝 모델이 필요한 데이터를 빠르게 처리하고 전달할 수 있게 합니다.
✅ 학습시 필요한 GPU 메모리 계산 방법
- 모델 파라미터의 크기:
- 각 레이어의 파라미터 개수를 계산하고, 각 파라미터의 데이터 타입 (보통 float32, 4바이트)을 곱합니다.
- 예: 파라미터 수×4바이트\text{파라미터 수} \times 4 \text{바이트}
- 활성화 맵(Activation Map)의 크기:
- 각 레이어에서 활성화 맵의 크기를 계산합니다. 입력 데이터의 배치 크기, 채널 수, 높이, 너비를 곱하여 계산합니다.
- 예: 배치 크기×채널 수×높이×너비×4바이트\text{배치 크기} \times \text{채널 수} \times \text{높이} \times \text{너비} \times 4 \text{바이트}
- 중간 계산 값의 크기:
- 순전파 및 역전파 시 중간 계산 값을 저장하는 데 필요한 메모리를 계산합니다.
- 배치 크기에 따른 메모리:
- 배치 크기가 클수록 필요한 메모리가 증가합니다. 메모리 사용량을 줄이기 위해 배치 크기를 적절히 조절해야 합니다.
총 메모리 계산 예시:
- 가령, CNN 모델에서 한 계층의 파라미터 수가 1,000,000개이고 배치 크기가 32, 입력 데이터 크기가 28×2828 \times 28인 경우:
- 파라미터 메모리: 1,000,000×4바이트=4MB
- 활성화 맵 메모리 (한 계층): 32×채널 수×28×28×4바이트
- 여러 계층에 대해 이 계산을 반복하여 총 메모리를 계산합니다.
계산 예시:
- 모델 파라미터 수: ∑각 계층의 파라미터 수×4바이트
- 활성화 맵 메모리: 배치 크기×∑각 계층의 활성화 맵 크기×4바이트
- 중간 계산 값 및 기타 필요 메모리도 포함하여 총 GPU 메모리를 추정합니다.
728x90
반응형
'AI & DATA > AI' 카테고리의 다른 글
| Google의 Titans: 인간과 유사한 기억력을 갖춘 신경망의 탄생 (1) | 2025.02.05 |
|---|---|
| AI개발자가 준비하는 면접 기초 개념 (1) (0) | 2024.05.29 |
| 우당탕탕 MLflow 입문기 (1) | 2024.05.07 |
| 딥러닝 프레임워크 비교 및 분석(Tensorflow / Keras / PyTorch) (0) | 2024.05.07 |