
일단,,,논문 전체를 번역 및 설명한 글 참고하세용...
https://bkshin.tistory.com/entry/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-YOLOYou-Only-Look-Once
논문 리뷰 - YOLO(You Only Look Once) 톺아보기
본 글은 YOLO 논문 전체를 번역 및 설명해놓은 글입니다. 크게 중요하지 않은 부분을 제외하고는 대부분의 글을 번역했고 필요하다면 부가적인 설명도 추가했습니다. 내용이 긴 섹션 끝에는 요약
bkshin.tistory.com
✅ YOLO란?
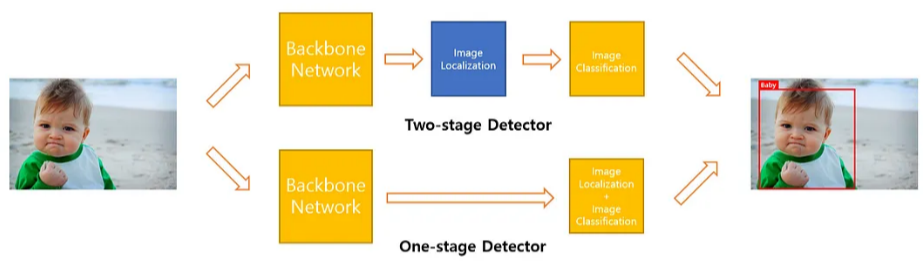
객체 탐지(Object Detection)에는 두 가지 방식이 존재하는데, Image Classification과 Localization을 구분짓는 "Two-stage Detector"와 두 과정을 구분짓지 않는 One-stage Detector가 있음.
- Two-stage Detector는 성능이 뛰어나지만 속도가 느리다는 단점이 있으며, 대표적인 모델로 실행속도가 5FPS인 Faster R-CNN이 있음.
- 반면 YOLO는 속도가 빠르다는 장점을 갖고 있으며, 한 번만 봐도 된다는 의미의 You Only Look Once에서 YOLO라는 이름이 나오게 됨
✅ Introduction
- 이전의 image detection : 객체를 감지하기 위해 이미지에서 region proposa 방법으로 bounding box를 생성한 후 box에서 분류를 실행하고, fine tuning과 중복된 box를 제거 ---> 속도가 느리고 최적화가 어려움
- object detectinon을 이미지 픽셀에서 bounding box coordinates와 클래스 확률을 도출해내는 것을 회귀 문제로 재구성
---> 전체 이미지를 한 번만 사용 가능

---> YOLO는 전체 이미지를 학습하고, object detection을 최적화하는 것을 알 수 있음
[ 이점 ]
1. detection을 회귀 문제로 간주하므로, 전체 파이프라인이 복잡하지 않고 빠른 속도를 가짐
2. object를 예측할 때 이미지에 대해 전체적으로 추론함 --> 이미지 배경을 object로 판단하는 오류가 낮다
3. object의 일반화 가능한 representation을 학습하므로, 새로운 도메인에 강력
[ 단점 ]
1. 최신 detection 방법들에 비해 정확도가 떨어짐
2. 그리드 셀보다 작은 object는 정확한 위치 찾기가 어려움
✅ Unified Detection
object detection의 개별 구성요소를 단일 신경망으로 통합하므로, end-to-end training과 real-time에 대한 높은 정밀도 유지

PASCAL VOC에서 YOLO를 평가하기 위해 S=7, B=2를 사용
동작원리

S x S grid on input : input 이미지 위에 가로 및 세로로 각각 s개의 격자 그리기
- 각 격자는 bbox와 각 bbox에 대한 신뢰도 점수를 예측
- 신뢰도 점수는 "bbox가 객체를 포함하는지에 대해 신뢰성이 있는지"와 "bbox가 얼마나 정확한지"를 반영
- confidence socre : 객체 존재 여부와 bbox의 정확도를 동시에 평가하는 지표

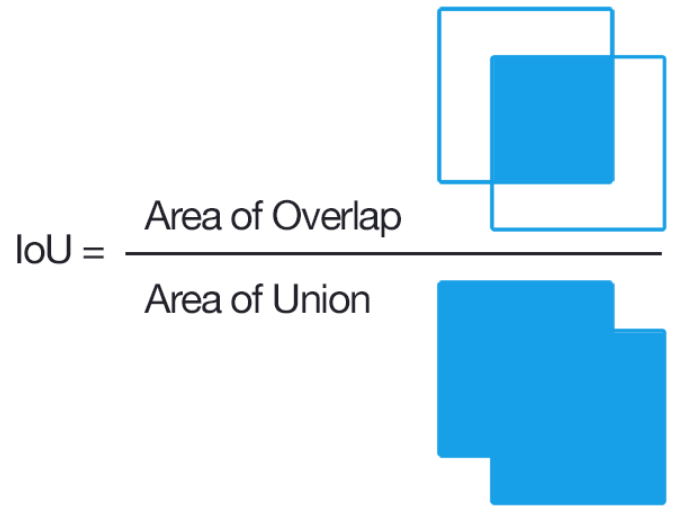
- IoU(Intersection over Union) : bbox의 위치 정확도 평가지표
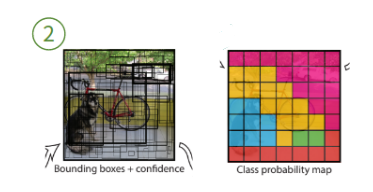
bbox & confidence score & class probability 예측
- bbox는 중심인 (x, y) 좌표, 높이와 너비 (w, h) 정보, 그리고 IoU 총 5개의 변수에 대한 예측을 진행
- '객체가 있다고 가정할 때, 특정 객체 (class)일 확률'이라는 조건부 확률을 예측 --> YOLO는 20개의 class를 지원하므로 20개의 확률정보를 담고 있음
- test를 할 때, 특정 class에 대한 신뢰도 점수 구하는 공식


final detections
- NMS를 통해 최종 detection을 결정내림
2.1) Network Design ★
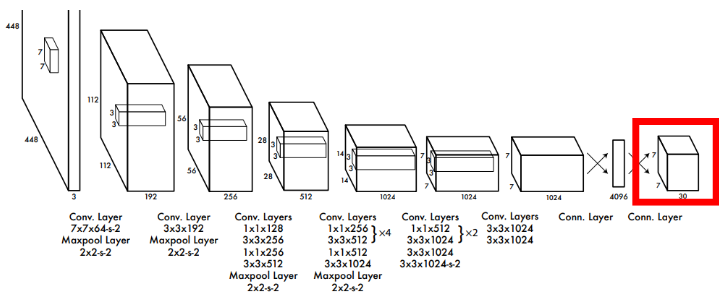
네트워크 아키텍처는 GoogLeNet을 기반으로 활용했고, 24개의 conv layer와 2개의 fc layer가 존재
중간중간에 max-pooling layer와 feature map의 demension을 줄이기 위한(parameter 수를 줄이기 위한) 1 x 1 convolution layer가 존재
out에 관한 자세한 내용은 아래 글 참고!!
[YOLO]You Only Look Once : Unified, Real-Time Object Detection
발표마다 세상을 놀라게 하는 YOLO 시리즈의 최초 모델인 YOLO v1 논문 완전 리뷰!
velog.io
2.2) Training
- layer에는 Leaky ReLU 사용

bbox 위치와 관련된 파트는 5를 곱하고, 객체가 없는 상황에 대한 파트는 0.5를 곱해 더해줌으로써 중요도를 loss에 반영
- 첫 번째 줄 : x, y 좌표를 truth와 prediction을 제곱하여 error 계산
- 두 번째 줄 : bounding box의 w, h에 대한 error를 루트를 씌워 계산
- 세 번째 줄 : object를 포함한 bounding box에 대한 confidence error 계산 (Ci = 1)
- 네 번째 줄 : object를 포함하지 않은 bounding box에 대한 confidence error 계산 9Ci =0)
- 마지막 줄 : p(c) 클래스에 대한 error 계산
[ 논문에서의 모델 학습 ]
- epoch = 135, batch size = 64, momentum = 0.9, decay = 0.005
- learning rate scheculing : 첫 epoch에서 0.001로 시작해서 75 epoch까지 0.01으로 학습. 이후 30 epochs 동안 0.001로 학습하고, 마지막 30 epochs 동안 0.0001으로 학습
- overfitting을 막기 위해 dropout(rate = 0.5)과 data augmentation을 활용
2.3) Inference
NMS(Non-maximal suppression, 비최대치 억제) : 다중 검출 문제를 해결하기 위해 각 클래스 별로 NMS 사용
---> 화소 강도 차이가 큰 edge(최대치)를 제외하고는 모두 억제
2번 part에 대한 더 자세한 내용은 아래 글 참고~~~~~~~
[논문 리뷰] You Only Look Once: Unified, Real-Time Object Detection
Abstract 이 논문에서는 object detection을 공간적으로 분리된 bounding box와 class 확률에 대한 회귀 문제로 설정한다. 단일 신경망을 사용하며 전체 이미지에서 직접 bounding box와 class 확률을 예측한다.
hhhhhsk.tistory.com
✅ Comparison to Other Detection Systems
- Deformable parts model(DPM)
sliding window 방식을 통해 detection을 수행하며, 정적 feature을 추출하고 영역을 분류하여 점수가 높은 영역에 대한 bounding box를 예측하는데 분리된 파이프라인을 사용
----> YOLO는 모든 부분을 단일 CNN으로 대체하며! 네트워크는 feature 추출, bounding box 예측, NMS 및 contextual reasoning을 동시에 수행
- R-CNN
이미지에서 object를 찾기 위해 region proposal을 사용
- Selective search : 잠재적 bounding box 및 CNN 추출 기능을 생성
- SVM : 점수 부여
- 선형 모델 : bounding box를 조정
- NMS : 중복된 탐지를 제거
이 복잡한 파이프라인의 각 단계는 독립적으로 fine-tuning해야 하며 매우 느려서 이미지당 40초 이상 소요
----> YOLO는 각 그리드 셀이 bounding box를 예측하고 그 box에 대해 점수를 계산한다는 부분에서 R-CNN과 유사하지만, YOLO는 각 그리드 셀의 공간적 제약 때문에 하나의 object가 여러 번 검출되는 경우가 R-CNN에 비해 적음. 또한 selective search의 약 2000개에 비해 이미지당 98개로 훨씬 적은 수의 bounding box를 제안하며, 이러한 개별 구성 요소를 공동으로 최적화된 단일 모델로 결합
✅ YOLO 적용 예
- 빠르고 정확한 object detector로써 컴퓨터 비전 애플리케이션에 이상적
- 웹캠에 연결하여 real time performance를 확인할 수 있음
https://www.youtube.com/watch?v=MPU2HistivI
✅ Conclusion
- YOLO는 object detection을 위한 Unified model, 즉 하나의 네트워크로 이루어진 모델
- 이 모델은 간단하며, 전체 이미지를 통해 직접적으로 학습할 수 있음
- 다른 classifier 기반의 접근 방식과 다르게, YOLO는 loss function을 통해 detection result에서 직접적으로 학습할 수 있고, 전체 모델이 연결되어있음
- Fast YOLO는 가장 빠른 object detector이고, YOLO는 real time detector중 최고 성능을 내고 있음
- 새로운 domain의 이미지에 대해서도 잘 일반화해 작동하여 빠르고 강건한 object detection을 위해 사용할 수 있음
'Paper Review' 카테고리의 다른 글
| <NLP> [Transformer] Attention Is All You Need (2017.06) (1) | 2024.07.30 |
|---|---|
| YOLO v3 : An Incremental Improvement (0) | 2024.05.13 |
| YOLO v2 : YOLO9000: Better, Faster, Stronger (0) | 2024.05.11 |
| Texture Synthesis Using Convolutional Neural Networks (0) | 2024.05.10 |
| A Neural Algorithm of Artistic Style (0) | 2024.05.10 |