
NLP 분야의 근본 논문 Attention Is All You Need를 리뷰해 보았습니당
🧮 논문 출처: https://arxiv.org/pdf/1706.03762
✅ Attention이란?
우선 논문 리뷰에 앞서,, Attention이란 간단하게 말해서 모든 기억을 동등하게 집중해서 기억하도록 구조화하는 기법입니다. 기존의 RNN(Recurrent Neural Networks)이나 LSTM(Long Short-Term Memory) 같은 순환 신경망 모델들은 입력 시퀀스를 순차적으로 처리하여 고정된 크기의 벡터로 인코딩한 후, 이를 디코더가 다시 출력 시퀀스로 변환합니다. 이 과정에서 중요한 정보가 손실되거나, 긴 시퀀스의 경우 앞부분의 정보가 희석되는 문제가 발생할 수 있습니다. 어텐션 메커니즘은 이러한 문제를 해결하기 위해 도입되었습니다.
하지만...초기 어텐션은 RNN, CNN 구조와 함께 사용되어 여전히 시퀀스 길이가 길어지면 같은 문제가 발생하는 한계가 있었습니다...! 그래서 문제를 해결하기 위해 이 논문에서와 같이 구글은 Transformer 모델을 제안하게 됩니다.
📍Transformer에서의 Attention
트랜스포머 모델은 어텐션 메커니즘을 극대화한 모델입니다. 트랜스포머는 순환이나 합성곱 연산 없이 오로지 어텐션 메커니즘만을 사용하여 모든 입력 단어들 사이의 관계를 동시다발적으로 고려합니다. 트랜스포머에서 사용되는 주요 어텐션 메커니즘은 셀프 어텐션(Self-Attention)입니다.
- 입력 시퀀스의 각 단어가 시퀀스 내 다른 모든 단어들과의 관계를 계산합니다.
- 각 단어의 표현을 계산할 때, 시퀀스 내 모든 단어의 정보가 반영되므로, 입력 시퀀스 전체의 컨텍스트를 더 잘 파악할 수 있습니다.
셀프 어텐션은 다중 헤드 어텐션(Multi-Head Attention)으로 확장되어, 입력 시퀀스를 서로 다른 하위 공간에서 여러 번 고려하여 더 풍부한 표현을 학습합니다. 즉, RNN, CNN 구조를 완전히 배제하고 Attention 자체에만 집중하는 것입니다!
✅ Introduction & Background
순환 신경망(Recurrent Neural Networks), 특히 LSTM과 GRU는 언어 모델링과 machine translation, sequence modeling과 같은 분야에서 주류를 이루고 있었습니다. 그러나 이러한 순환 모델들은 입력 및 출력 시퀀스의 심볼 위치를 따라 계산을 분할하여, 병렬화를 어렵게 만들고 sequential computation의 근본적 한계가 존재했습니다.
Attention mechanism은 이러한 제약을 극복하고 다양한 작업에서 의존성을 모델링하는 데 중요한 역할을 하지만, 대부분의 경우 순환 네트워크와 함께 사용됩니다...
그래서!! 본 논문에서는 순환을 배제하고 오로지 Attention mechanism에 의존하여 입력과 출력을 연결하는 새로운 모델 아키텍처인 트랜스포머를 제안합니다. 트랜스포머는 병렬화를 크게 향상시키며, 8개의 P100 GPU로 12시간만 훈련해도 번역 품질에서 새로운 최고 성능을 달성할 수 있습니다.
➕ ➕
sequential computation을 줄이려는 목표는 Extended Neural GPU, ByteNet, ConvS2S와 같은 모델들의 기반이 되었으며, 이들은 합성곱 신경망(CNN)을 기본 블록으로 사용하여 모든 입력 및 출력 위치에 대해 병렬로 숨겨진 표현을 계산합니다. 이러한 모델에서는 두 위치 사이의 신호를 연관시키는 데 필요한 연산 수가 위치 간 거리에 비례하여 증가합니다. 트랜스포머는 이를 상수 연산 수로 줄이지만, 어텐션 가중치가 평균화되는 효과로 인해 해상도가 감소할 수 있습니다.
이를 보완하기 위해 다중 헤드 어텐션(Multi-Head Attention)을 사용합니다. 셀프 어텐션(Self-Attention)은 단일 시퀀스의 다른 위치를 연관시켜 시퀀스의 표현을 계산하는 메커니즘으로, 다양한 작업에서 성공적으로 사용되고 있습니다. 트랜스포머는 셀프 어텐션만을 사용하여 입력과 출력의 표현을 계산하는 최초의 변환 모델로, 시퀀스 정렬 RNN이나 합성곱을 사용하지 않습니다.
✅ Model Architecture
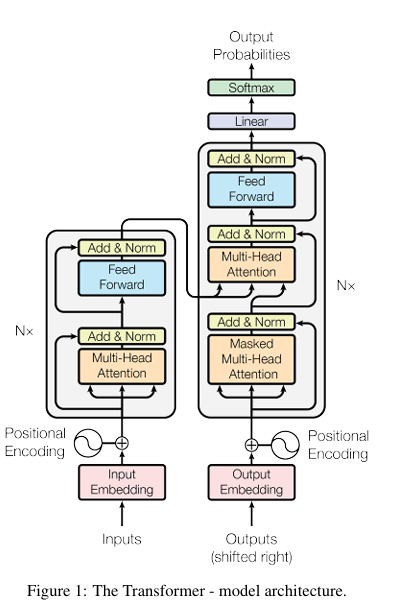
입력 시퀀스는 x = (x1, x2, ..., xn), 이를 continuous representation으로 만든 것이 z = (z1, z2, ..., zn), decoder가 만들어내는 output sequence를 (y1, y2, ..., ym)으로 표기합니다.
📍Encoder and Decoder Stacks
인코더:
- 인코더는 동일한 6개의 레이어로 구성됩니다.
- 각 레이어는 두 개의 서브 레이어로 구성됩니다:
- 다중 헤드 셀프 어텐션 메커니즘
- 위치별 완전 연결 피드 포워드 네트워크
- 각 서브 레이어 주위에 잔차 연결(residual connection)을 사용하고, 그 후 레이어 정규화(layer normalization)를 수행합니다.
- 서브 레이어와 임베딩 레이어의 출력 차원은 모두 dmodel=512입니다.
디코더:
- 디코더도 동일한 6개의 레이어로 구성됩니다.
- 각 인코더 레이어의 두 서브 레이어 외에도, 디코더에는 인코더 스택의 출력에 대해 다중 헤드 어텐션을 수행하는 세 번째 서브 레이어가 추가됩니다.
- 디코더 스택의 셀프 어텐션 서브 레이어는 다음 위치를 참조하지 못하도록 수정하여, 위치 ii에 대한 예측이 ii보다 작은 위치의 출력에만 의존하도록 합니다.
📍Attentinon
어텐션 함수는 쿼리(query)와 일련의 키-값 쌍을 출력으로 매핑하는 것으로, 쿼리, 키, 값, 출력 모두 벡터입니다. 출력은 쿼리와 각 키의 유사도를 계산하여 얻은 가중치를 각 값에 곱한 가중 합으로 계산됩니다.
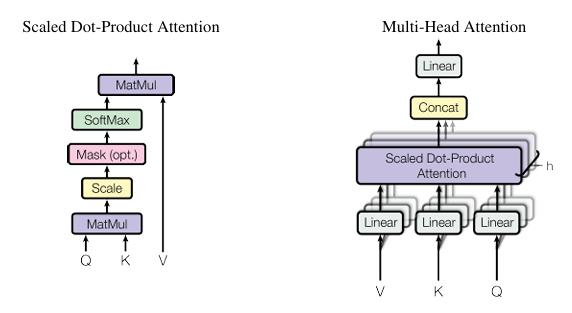
- Scaled Dot-Product Attention
- 입력은 차원이 dk인 쿼리와 키, dv인 값을 포함합니다.
- 쿼리와 모든 키의 내적 연산에 키 차원의 1/2승 만큼 나누는 것을 제외하면 additive attention과 동일합니다.
- 하지만 차원(dk)가 커짐에 따라 softmax function이 너무 작은 gradient를 가질 가능성이 높아져, 루트 dk로 나눈 후 소프트맥스 함수를 적용해 가중치를 얻어야 합니다.
- Multi-Head Attention
- 쿼리, 키, value를 h번 다르게 linearly project(선영 투영)한 후 어텐션 함수를 병렬로 수행하여 dv 차원의 출력을 얻습니다.
- h=8의 병렬 어텐션을 사용하며, 각 헤드의 차원은 dk=dv=dmodel/h=64 가 됩니다.
- 모델에서의 Attention 응용트랜스포머는 세 가지 방식으로 멀티-헤드 어텐션을 사용합니다.
- 인코더-디코더 어텐션: 쿼리는 이전 디코더 레이어에서 오고, 메모리 키와 값은 인코더의 출력에서 옵니다. 이는 디코더의 모든 위치가 입력 시퀀스의 모든 위치를 참조할 수 있게 합니다.
- 인코더 셀프 어텐션: 키, 값, 쿼리 모두 인코더의 이전 레이어 출력에서 나옵니다. 인코더의 각 위치는 이전 레이어의 모든 위치를 참조할 수 있습니다.
- 디코더 셀프 어텐션: 디코더의 각 위치는 디코더의 현재 위치까지의 모든 위치를 참조할 수 있습니다. 자기회귀 특성을 유지하기 위해 디코더의 왼쪽 방향 정보 흐름을 방지해야 합니다. 이를 위해 Scaled Dot-Product Attention 내부에서 소프트맥스 입력의 불법 연결에 해당하는 값을 무한대로 설정하는 마스킹을 사용합니다.
📍 Position-wise Feed-Forward Networks
- 인코더와 디코더 모두 attention sub-layer 외에도 위치별로 동일하게 적용되는 fully connected feed-forward network를 적용합니다.
- fully connected feed-forward network는 두 개의 선형 변환과 그 사이에 ReLU 활성화를 포함하며, 각 위치마다 동일한 선형 변환이 적용되지만, 레이어마다 다른 매개변수를 사용합니다.
- 입력과 출력의 차원은 dmodel = 512, 내부 레이어의 차원은 dff = 2048 !!!
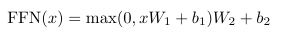
📍 Embeddings and Softmax
- 입력토큰과 출력토큰을 dmodel 차원의 벡터로 변환하기 위해 학습된 임베딩을 사용합니다.
- 디코더 출력은 예측된 다음 토큰의 확률로 변환하기 위해 학습된 선형 변환과 소프트맥스 함수를 사용합니다.
- 본 논문의 모델에서는 두 임베딩 레이어와 소프트맥스 이전의 선형 변환에서 동일한 가중치 행렬을 사용합니다!
- 임베딩 레이어에서는 이 가중치를 루트 dmodel로 곱합니다.
📍 Positional Encoding
모델에 순환이나 합성곱이 없기 때문에, 시퀀스의 순서를 반영하기 위해 토큰의 상대적 또는 절대적 위치에 대한 정보를 주입해야 하며, 그래서 인코더와 디코더 stack의 맨 아래에서 입력 임베딩에 "Positional Encoding"을 추가해야 합니다.
아래 그림과 같은 다양한 sin, cos 함수를 사용했습니다.
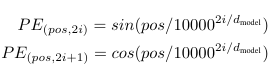
✅ Why Self-Attention
Self-Attention을 사용하는 이유는 크게 3가지 입니다.
1. layer 당 computational complexity가 낮음
2. 병렬화 할 수 있는 computation의 amount가 큼
3. 네트워크 내에서 long-range의 의존성을 가짐

+) 추가적으로, self-attention은 interpretable하다는 특징을 지님
✅ Training & Result
학습과 결과 부분은 간단하게 리뷰하겠습니다.
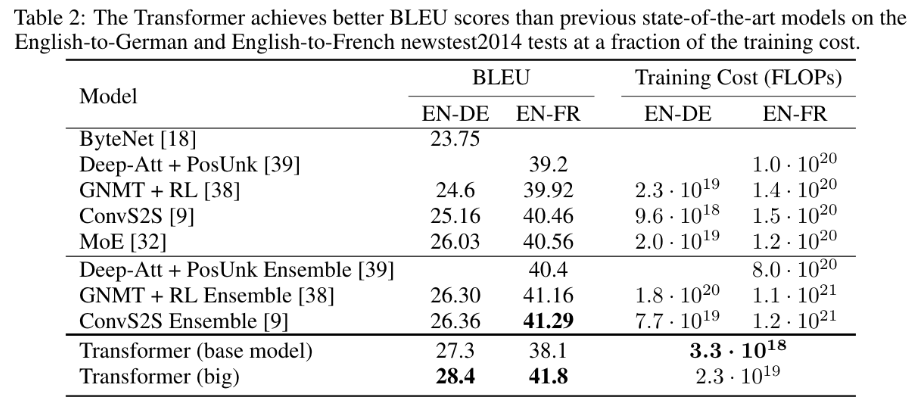
결론적으로는 영어->독일어 번역, 영어->불어 번역 수행에 있어 다른 기존의 SOTA 모델과 비교해 월등한 최고 성능을 보여줬다고 합니다!
모델링 할 때 주의점은 HEAD 개수 적당히, d_{k}를 줄이면 모델 성능 저하로 이어짐, 모델 사이즈가 커질 수록 성능이 좋아지며, dropout은 오버피팅 방지에 도움을 준다...? 정도가 있었습니다.
✅ My Insight
트랜스포머 모델은 계속 발전되고 있으며, 이 논문은 여전히 최신 생성형 모델의 바이블...근본이지 않을까...싶습니다. 그리고 이러한 새로운 아이디어를 떠올리고 구현하는 이 과정이 너무 머찝니다...뇌섹피플들...
나는 트랜스포머에 대해 무지렁이었구나 그냥 유명하고 자주 쓰이니 친숙했을 뿐이구나를 다시 한 번 깨닫네요.
self-attention과 attention이 다른 점을 깨닫게 되었고, 이 논문이 써질 당시에는 RNN, CNN 대비 효율적이었다는 사실이 흥미로웠습니다.
더 공부하자.....화이팅...!
'Paper Review' 카테고리의 다른 글
| YOLO v3 : An Incremental Improvement (0) | 2024.05.13 |
|---|---|
| YOLO v2 : YOLO9000: Better, Faster, Stronger (0) | 2024.05.11 |
| YOLO : You Only Look Once: Unified, Real-Time Object Detection (0) | 2024.05.11 |
| Texture Synthesis Using Convolutional Neural Networks (0) | 2024.05.10 |
| A Neural Algorithm of Artistic Style (0) | 2024.05.10 |
NLP 분야의 근본 논문 Attention Is All You Need를 리뷰해 보았습니당
🧮 논문 출처: https://arxiv.org/pdf/1706.03762
✅ Attention이란?
우선 논문 리뷰에 앞서,, Attention이란 간단하게 말해서 모든 기억을 동등하게 집중해서 기억하도록 구조화하는 기법입니다. 기존의 RNN(Recurrent Neural Networks)이나 LSTM(Long Short-Term Memory) 같은 순환 신경망 모델들은 입력 시퀀스를 순차적으로 처리하여 고정된 크기의 벡터로 인코딩한 후, 이를 디코더가 다시 출력 시퀀스로 변환합니다. 이 과정에서 중요한 정보가 손실되거나, 긴 시퀀스의 경우 앞부분의 정보가 희석되는 문제가 발생할 수 있습니다. 어텐션 메커니즘은 이러한 문제를 해결하기 위해 도입되었습니다.
하지만...초기 어텐션은 RNN, CNN 구조와 함께 사용되어 여전히 시퀀스 길이가 길어지면 같은 문제가 발생하는 한계가 있었습니다...! 그래서 문제를 해결하기 위해 이 논문에서와 같이 구글은 Transformer 모델을 제안하게 됩니다.
📍Transformer에서의 Attention
트랜스포머 모델은 어텐션 메커니즘을 극대화한 모델입니다. 트랜스포머는 순환이나 합성곱 연산 없이 오로지 어텐션 메커니즘만을 사용하여 모든 입력 단어들 사이의 관계를 동시다발적으로 고려합니다. 트랜스포머에서 사용되는 주요 어텐션 메커니즘은 셀프 어텐션(Self-Attention)입니다.
- 입력 시퀀스의 각 단어가 시퀀스 내 다른 모든 단어들과의 관계를 계산합니다.
- 각 단어의 표현을 계산할 때, 시퀀스 내 모든 단어의 정보가 반영되므로, 입력 시퀀스 전체의 컨텍스트를 더 잘 파악할 수 있습니다.
셀프 어텐션은 다중 헤드 어텐션(Multi-Head Attention)으로 확장되어, 입력 시퀀스를 서로 다른 하위 공간에서 여러 번 고려하여 더 풍부한 표현을 학습합니다. 즉, RNN, CNN 구조를 완전히 배제하고 Attention 자체에만 집중하는 것입니다!
✅ Introduction & Background
순환 신경망(Recurrent Neural Networks), 특히 LSTM과 GRU는 언어 모델링과 machine translation, sequence modeling과 같은 분야에서 주류를 이루고 있었습니다. 그러나 이러한 순환 모델들은 입력 및 출력 시퀀스의 심볼 위치를 따라 계산을 분할하여, 병렬화를 어렵게 만들고 sequential computation의 근본적 한계가 존재했습니다.
Attention mechanism은 이러한 제약을 극복하고 다양한 작업에서 의존성을 모델링하는 데 중요한 역할을 하지만, 대부분의 경우 순환 네트워크와 함께 사용됩니다...
그래서!! 본 논문에서는 순환을 배제하고 오로지 Attention mechanism에 의존하여 입력과 출력을 연결하는 새로운 모델 아키텍처인 트랜스포머를 제안합니다. 트랜스포머는 병렬화를 크게 향상시키며, 8개의 P100 GPU로 12시간만 훈련해도 번역 품질에서 새로운 최고 성능을 달성할 수 있습니다.
➕ ➕
sequential computation을 줄이려는 목표는 Extended Neural GPU, ByteNet, ConvS2S와 같은 모델들의 기반이 되었으며, 이들은 합성곱 신경망(CNN)을 기본 블록으로 사용하여 모든 입력 및 출력 위치에 대해 병렬로 숨겨진 표현을 계산합니다. 이러한 모델에서는 두 위치 사이의 신호를 연관시키는 데 필요한 연산 수가 위치 간 거리에 비례하여 증가합니다. 트랜스포머는 이를 상수 연산 수로 줄이지만, 어텐션 가중치가 평균화되는 효과로 인해 해상도가 감소할 수 있습니다.
이를 보완하기 위해 다중 헤드 어텐션(Multi-Head Attention)을 사용합니다. 셀프 어텐션(Self-Attention)은 단일 시퀀스의 다른 위치를 연관시켜 시퀀스의 표현을 계산하는 메커니즘으로, 다양한 작업에서 성공적으로 사용되고 있습니다. 트랜스포머는 셀프 어텐션만을 사용하여 입력과 출력의 표현을 계산하는 최초의 변환 모델로, 시퀀스 정렬 RNN이나 합성곱을 사용하지 않습니다.
✅ Model Architecture
입력 시퀀스는 x = (x1, x2, ..., xn), 이를 continuous representation으로 만든 것이 z = (z1, z2, ..., zn), decoder가 만들어내는 output sequence를 (y1, y2, ..., ym)으로 표기합니다.
📍Encoder and Decoder Stacks
인코더:
- 인코더는 동일한 6개의 레이어로 구성됩니다.
- 각 레이어는 두 개의 서브 레이어로 구성됩니다:
- 다중 헤드 셀프 어텐션 메커니즘
- 위치별 완전 연결 피드 포워드 네트워크
- 각 서브 레이어 주위에 잔차 연결(residual connection)을 사용하고, 그 후 레이어 정규화(layer normalization)를 수행합니다.
- 서브 레이어와 임베딩 레이어의 출력 차원은 모두 dmodel=512입니다.
디코더:
- 디코더도 동일한 6개의 레이어로 구성됩니다.
- 각 인코더 레이어의 두 서브 레이어 외에도, 디코더에는 인코더 스택의 출력에 대해 다중 헤드 어텐션을 수행하는 세 번째 서브 레이어가 추가됩니다.
- 디코더 스택의 셀프 어텐션 서브 레이어는 다음 위치를 참조하지 못하도록 수정하여, 위치 ii에 대한 예측이 ii보다 작은 위치의 출력에만 의존하도록 합니다.
📍Attentinon
어텐션 함수는 쿼리(query)와 일련의 키-값 쌍을 출력으로 매핑하는 것으로, 쿼리, 키, 값, 출력 모두 벡터입니다. 출력은 쿼리와 각 키의 유사도를 계산하여 얻은 가중치를 각 값에 곱한 가중 합으로 계산됩니다.
- Scaled Dot-Product Attention
- 입력은 차원이 dk인 쿼리와 키, dv인 값을 포함합니다.
- 쿼리와 모든 키의 내적 연산에 키 차원의 1/2승 만큼 나누는 것을 제외하면 additive attention과 동일합니다.
- 하지만 차원(dk)가 커짐에 따라 softmax function이 너무 작은 gradient를 가질 가능성이 높아져, 루트 dk로 나눈 후 소프트맥스 함수를 적용해 가중치를 얻어야 합니다.
- Multi-Head Attention
- 쿼리, 키, value를 h번 다르게 linearly project(선영 투영)한 후 어텐션 함수를 병렬로 수행하여 dv 차원의 출력을 얻습니다.
- h=8의 병렬 어텐션을 사용하며, 각 헤드의 차원은 dk=dv=dmodel/h=64 가 됩니다.
- 모델에서의 Attention 응용트랜스포머는 세 가지 방식으로 멀티-헤드 어텐션을 사용합니다.
- 인코더-디코더 어텐션: 쿼리는 이전 디코더 레이어에서 오고, 메모리 키와 값은 인코더의 출력에서 옵니다. 이는 디코더의 모든 위치가 입력 시퀀스의 모든 위치를 참조할 수 있게 합니다.
- 인코더 셀프 어텐션: 키, 값, 쿼리 모두 인코더의 이전 레이어 출력에서 나옵니다. 인코더의 각 위치는 이전 레이어의 모든 위치를 참조할 수 있습니다.
- 디코더 셀프 어텐션: 디코더의 각 위치는 디코더의 현재 위치까지의 모든 위치를 참조할 수 있습니다. 자기회귀 특성을 유지하기 위해 디코더의 왼쪽 방향 정보 흐름을 방지해야 합니다. 이를 위해 Scaled Dot-Product Attention 내부에서 소프트맥스 입력의 불법 연결에 해당하는 값을 무한대로 설정하는 마스킹을 사용합니다.
📍 Position-wise Feed-Forward Networks
- 인코더와 디코더 모두 attention sub-layer 외에도 위치별로 동일하게 적용되는 fully connected feed-forward network를 적용합니다.
- fully connected feed-forward network는 두 개의 선형 변환과 그 사이에 ReLU 활성화를 포함하며, 각 위치마다 동일한 선형 변환이 적용되지만, 레이어마다 다른 매개변수를 사용합니다.
- 입력과 출력의 차원은 dmodel = 512, 내부 레이어의 차원은 dff = 2048 !!!
📍 Embeddings and Softmax
- 입력토큰과 출력토큰을 dmodel 차원의 벡터로 변환하기 위해 학습된 임베딩을 사용합니다.
- 디코더 출력은 예측된 다음 토큰의 확률로 변환하기 위해 학습된 선형 변환과 소프트맥스 함수를 사용합니다.
- 본 논문의 모델에서는 두 임베딩 레이어와 소프트맥스 이전의 선형 변환에서 동일한 가중치 행렬을 사용합니다!
- 임베딩 레이어에서는 이 가중치를 루트 dmodel로 곱합니다.
📍 Positional Encoding
모델에 순환이나 합성곱이 없기 때문에, 시퀀스의 순서를 반영하기 위해 토큰의 상대적 또는 절대적 위치에 대한 정보를 주입해야 하며, 그래서 인코더와 디코더 stack의 맨 아래에서 입력 임베딩에 "Positional Encoding"을 추가해야 합니다.
아래 그림과 같은 다양한 sin, cos 함수를 사용했습니다.
✅ Why Self-Attention
Self-Attention을 사용하는 이유는 크게 3가지 입니다.
1. layer 당 computational complexity가 낮음
2. 병렬화 할 수 있는 computation의 amount가 큼
3. 네트워크 내에서 long-range의 의존성을 가짐
+) 추가적으로, self-attention은 interpretable하다는 특징을 지님
✅ Training & Result
학습과 결과 부분은 간단하게 리뷰하겠습니다.
결론적으로는 영어->독일어 번역, 영어->불어 번역 수행에 있어 다른 기존의 SOTA 모델과 비교해 월등한 최고 성능을 보여줬다고 합니다!
모델링 할 때 주의점은 HEAD 개수 적당히, d_{k}를 줄이면 모델 성능 저하로 이어짐, 모델 사이즈가 커질 수록 성능이 좋아지며, dropout은 오버피팅 방지에 도움을 준다...? 정도가 있었습니다.
✅ My Insight
트랜스포머 모델은 계속 발전되고 있으며, 이 논문은 여전히 최신 생성형 모델의 바이블...근본이지 않을까...싶습니다. 그리고 이러한 새로운 아이디어를 떠올리고 구현하는 이 과정이 너무 머찝니다...뇌섹피플들...
나는 트랜스포머에 대해 무지렁이었구나 그냥 유명하고 자주 쓰이니 친숙했을 뿐이구나를 다시 한 번 깨닫네요.
self-attention과 attention이 다른 점을 깨닫게 되었고, 이 논문이 써질 당시에는 RNN, CNN 대비 효율적이었다는 사실이 흥미로웠습니다.
더 공부하자.....화이팅...!
'Paper Review' 카테고리의 다른 글
| YOLO v3 : An Incremental Improvement (0) | 2024.05.13 |
|---|---|
| YOLO v2 : YOLO9000: Better, Faster, Stronger (0) | 2024.05.11 |
| YOLO : You Only Look Once: Unified, Real-Time Object Detection (0) | 2024.05.11 |
| Texture Synthesis Using Convolutional Neural Networks (0) | 2024.05.10 |
| A Neural Algorithm of Artistic Style (0) | 2024.05.10 |