
논문은 3개의 파트로 구성되어 있음
- Better : 정확도를 올리기 위한 방법
- Faster : detection 속도를 향상시키기 위한 방법
- Stronger : 더 많은 범위의 class를 예측하기 위한 방법
✅ Better
- Batch Normalization
- 모든 conv layer 뒤에 batch normalization을 추가하여, 성능면에서 mAP 값 2% 향상
- overfitting 없이 기타 정규화 방법을 이용하여 dropout 제거
- High Resolution Classifier
- YOLO는 224×224로 classifier를 학습시키고 448×448로 사이즈를 키워서 detection을 수행했지만, YOLOv2는 classification network를 먼저 448×448 사이즈로 10 epoch 학습
- 네트워크는 더 큰 이미지에 대해 성능이 좋아지며, 성능명에서 mAP* 값 4% 향상
* mAP란? https://bskyvision.com/465
물체 검출 알고리즘 성능 평가방법 AP(Average Precision)의 이해
물체 검출(object detection) 알고리즘의 성능은 precision-recall 곡선과 average precision(AP)로 평가하는 것이 대세다. 이에 대해서 이해하려고 한참을 구글링했지만 초보자가 이해하기에 적당한 문서는 찾
bskyvision.com
- Convolutional with Anchor Boxes
- YOLO : convolutional feature extractor 바로 뒤에 fully connected layer를 쌓아서 bounding box를 바로 예측
- Faster R-CNN : FC layer로 이루어진 Region Proposal Network를 이용해 사전에 정의한 9개의 anchor box별로 offset(aspect ratio) 조정 및 confidence 예측
- YOLO v2 : FC layer를 제거하고, anchor box를 이용해서 bounding box를 예측
· 448×448가 아닌 416×416 크기의 이미지를 사용 --> 최종 output feature map의 크기가 홀수가 되도록 하여, feature map 내에 단 하나의 center cell이 존재하게 하기 위함
· spatial location에서 class를 예측하지 않고, 각 anchor box별로 class와 objectness를 예측 --> 약간의 성능 감소는 있지만, recall은 증가
- Dimension Clusters
- K-means clustering : 기존 anchor box 크기과 aspect ratio를 사전에 미리 정의한 "hand-picked"의 한계를 보완, 최적의 prior(사전조건) 탐색 방법 제시
· 데이터셋에 있는 모든 ground truth box의 width, height 값을 사용하여 수행
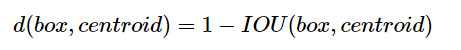
· 일반적인 K-means clustering은 유클리디안 거리를 통해 centroid와 sample간의 거리를 계산하는데, 이를 사용하는 경우 큰 bounding box는 작은 box에 비해 큰 error를 발생시키는 문제가 발생 ---> 새로운 distance metric 사용
- 새로운 distance metric : box의 크기와 무관하게 선택한 prior이 좋은 IoU 값을 가지도록 --> box와 centroid의 IoU 값이 클수록 겹치는 영역이 커 거리가 가까움
· k=5일 때, 모델의 복잡도와 recall 값이 적절한 trade-off 보여줌

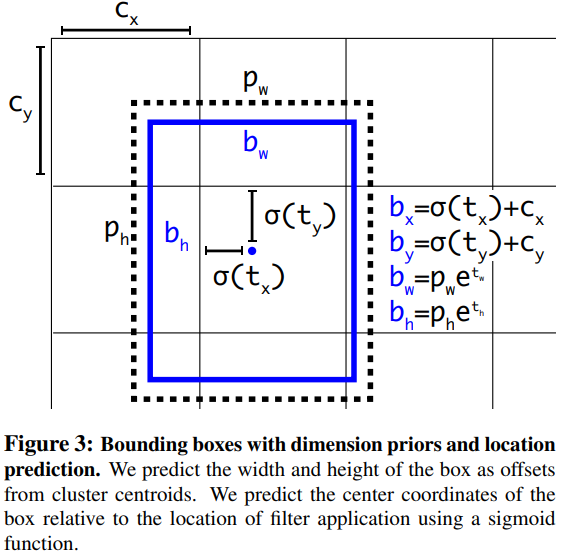
- Direct location prediction
- 초기 모델의 불안정함 : YOLO와 anchor box를 함께 사용하면 초기 iteration 시, 모델이 불안정함. anchor box는 bounding box regressor 계수를 통해 bounding box의 위치를 조정하는데, 계수는 제한 범위가 없기 때문에 anchor box는 이미지 내의 임의 지점에 위치할 수 있게 됨 --> 최적화 값 찾기 오래걸림
- 개선 : offset 예측하지 않고, grid cell에 기반해서 상대적인 location 예측 --> recall 값 5%정도 향상
- Fine-Grained Features
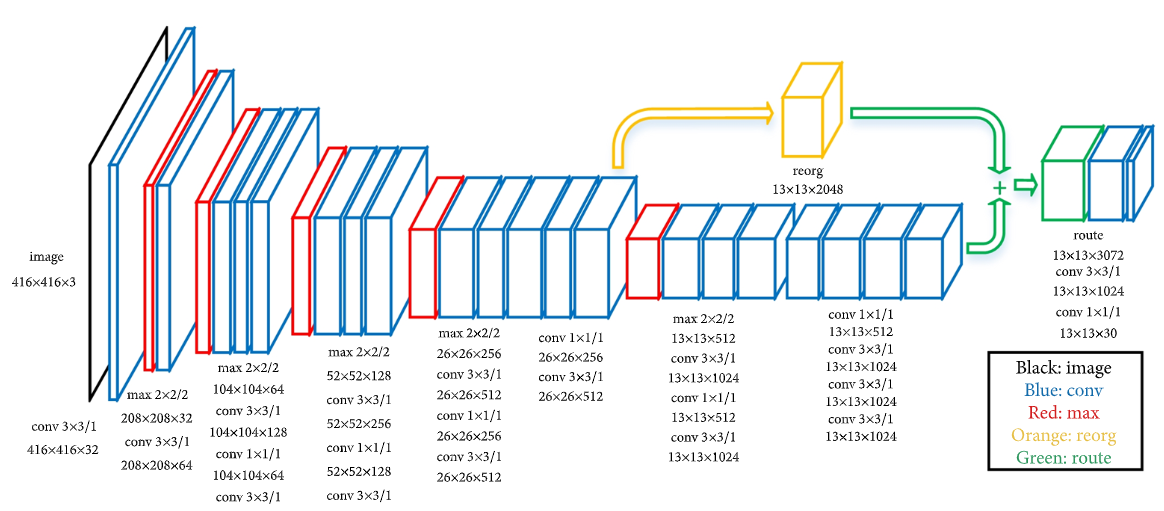
YOLO v2 architecture
modified YOLO는 13×13feature map에서 detection을 진행하는데 작은 object에는 효과적이지 않아, 더 앞에 있는 layer에서 26×26 크기의 feature를 가져오는 passthrough layer를 추가
--> 26×26×512 feature map을 13×13×2048 feature map으로 바꿔서 기존의 feature와 합칠 수 있음
--> 약 1%의 성능 향상
- Multi-scale training
- YOLO v2 모델을 보다 강건하게 만들기 위해 다양한 입력 이미지를 사용하여 네트워크를 학습시킴
- 10 batch마다 입력 이미지의 크기를 랜덤하게 선택하여 학습하도록 설계
- 이미지를 1/32배로 downsample시키기 때문에 입력 이미지 크기를 32배수 {320, 352, ..., 608} 중에서 선택하도록 함 (320x320 크기의 이미지가 가장 작은 입력 이미지이며, 608x608 크기의 이미지가 입력될 수 있는 가장 큰 이미지)
--> 네트워크는 다양한 크기의 이미지를 입력받을 수 있고, 속도와 정확도 사이의 trade-off를 제공
--> 입력 이미지의 크기가 작은 경우 더 높은 FPS를 가지며, 입력 이미지의 크기가 큰 경우 더 높은 mAP 값을 가지게 됨
✅ Faster
- Darknet-19 : 새로운 classification model
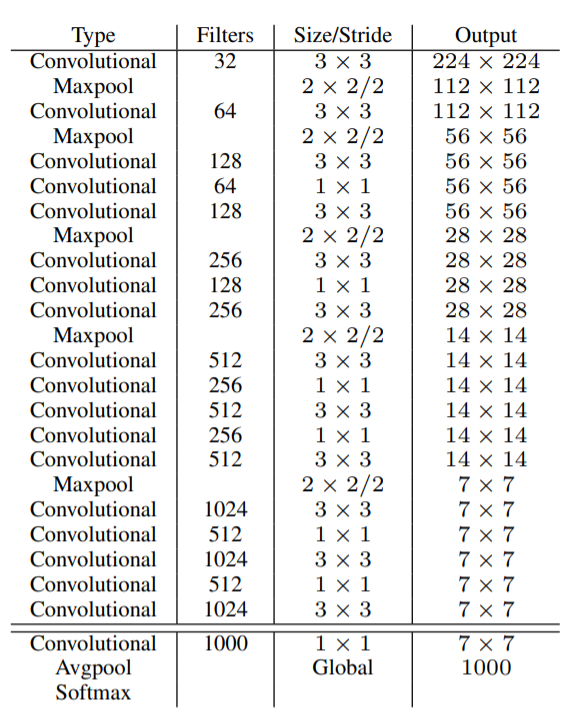
- VGG처럼 3×3크기의 필터를 사용, 매 pooling 단계 이후에 channel의 수를 두배로 늘림
- 3×3 conv 사이에 1×1 filter를 사용해서 feature representation을 압축
- 마지막 layer global average pooling을 사용하여 fc layer 제거 및 파라미터 수 감소
- Batch Normalization을 사용해서 학습이 안정적으로 학습되고, 빠르게 수렴되도록 함
- Training for calssification
- class 수가 1000개인 ImageNet 데이터셋을 통해 학습시킴(global average pooling 후 output 수가 1000개이므로)
--> top-1 정확도는 76.5%, top-5 정확도는 93.9% 성능
- 논문 : 224×224크리고 160 epoch 학습 후, 448×448 크기로 10 epoch 학습시켜 fine tuning
- Training for detection
Darknet-19를 detection task로 사용하기 위해 마지막 conv layer를 제거하고 1024 filter를 가진 3x3 conv layer로 대체후 1x1 conv layer를 추가
* 1x1 conv layer의 channel 수 : 예측할 때 필요한 수로, 각 grid cell마다 5개의 bounding box가 5개의 값(confidence score, x, y, w, h)과 PASCAL VOC 데이터셋을 사용하여 학습하기 때문에 20개의 class score를 예측
--> 1x1 conv layer에서 channel 수를 125(=5x(5+20))개로 지정
✅ Stronger
YOLO v2를 classification 데이터와 detection 데이터를 함께 사용하여 학습시킴으로써 보다 많은 class를 예측하는 YOLO 9000을 소개
--> classification 데이터와 detection 데이터를 섞어 학습
--> classification 데이터는 "요크셔테리어", "베들링턴테리어"와 같은 정확한 label을 가지나, detection 데이터는 "개"나 "배"와 같은 일반화된 label을 가짐
--> multi-label model 사용
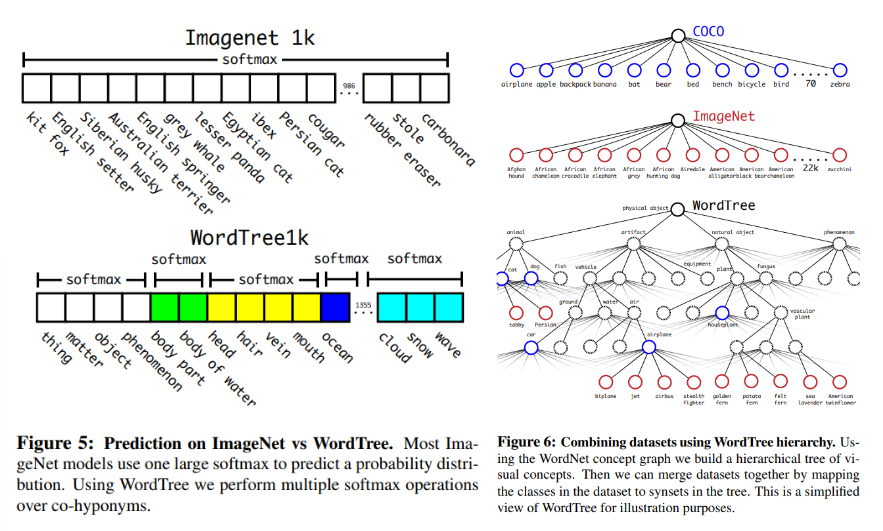
- Hierarchical classification
ImageNet label로부터 계층적인 트리인 WordTree를 구성하여 classification 데이터와 detection 데이터 모두 사용 --> 모든 노드에 대해 conditional probability 계산
'Paper Review' 카테고리의 다른 글
| <NLP> [Transformer] Attention Is All You Need (2017.06) (0) | 2024.07.30 |
|---|---|
| YOLO v3 : An Incremental Improvement (0) | 2024.05.13 |
| YOLO : You Only Look Once: Unified, Real-Time Object Detection (0) | 2024.05.11 |
| Texture Synthesis Using Convolutional Neural Networks (0) | 2024.05.10 |
| A Neural Algorithm of Artistic Style (0) | 2024.05.10 |
논문은 3개의 파트로 구성되어 있음
- Better : 정확도를 올리기 위한 방법
- Faster : detection 속도를 향상시키기 위한 방법
- Stronger : 더 많은 범위의 class를 예측하기 위한 방법
✅ Better
- Batch Normalization
- 모든 conv layer 뒤에 batch normalization을 추가하여, 성능면에서 mAP 값 2% 향상
- overfitting 없이 기타 정규화 방법을 이용하여 dropout 제거
- High Resolution Classifier
- YOLO는 224×224로 classifier를 학습시키고 448×448로 사이즈를 키워서 detection을 수행했지만, YOLOv2는 classification network를 먼저 448×448 사이즈로 10 epoch 학습
- 네트워크는 더 큰 이미지에 대해 성능이 좋아지며, 성능명에서 mAP* 값 4% 향상
* mAP란? https://bskyvision.com/465
물체 검출 알고리즘 성능 평가방법 AP(Average Precision)의 이해
물체 검출(object detection) 알고리즘의 성능은 precision-recall 곡선과 average precision(AP)로 평가하는 것이 대세다. 이에 대해서 이해하려고 한참을 구글링했지만 초보자가 이해하기에 적당한 문서는 찾
bskyvision.com
- Convolutional with Anchor Boxes
- YOLO : convolutional feature extractor 바로 뒤에 fully connected layer를 쌓아서 bounding box를 바로 예측
- Faster R-CNN : FC layer로 이루어진 Region Proposal Network를 이용해 사전에 정의한 9개의 anchor box별로 offset(aspect ratio) 조정 및 confidence 예측
- YOLO v2 : FC layer를 제거하고, anchor box를 이용해서 bounding box를 예측
· 448×448가 아닌 416×416 크기의 이미지를 사용 --> 최종 output feature map의 크기가 홀수가 되도록 하여, feature map 내에 단 하나의 center cell이 존재하게 하기 위함
· spatial location에서 class를 예측하지 않고, 각 anchor box별로 class와 objectness를 예측 --> 약간의 성능 감소는 있지만, recall은 증가
- Dimension Clusters
- K-means clustering : 기존 anchor box 크기과 aspect ratio를 사전에 미리 정의한 "hand-picked"의 한계를 보완, 최적의 prior(사전조건) 탐색 방법 제시
· 데이터셋에 있는 모든 ground truth box의 width, height 값을 사용하여 수행
· 일반적인 K-means clustering은 유클리디안 거리를 통해 centroid와 sample간의 거리를 계산하는데, 이를 사용하는 경우 큰 bounding box는 작은 box에 비해 큰 error를 발생시키는 문제가 발생 ---> 새로운 distance metric 사용
- 새로운 distance metric : box의 크기와 무관하게 선택한 prior이 좋은 IoU 값을 가지도록 --> box와 centroid의 IoU 값이 클수록 겹치는 영역이 커 거리가 가까움
· k=5일 때, 모델의 복잡도와 recall 값이 적절한 trade-off 보여줌
- Direct location prediction
- 초기 모델의 불안정함 : YOLO와 anchor box를 함께 사용하면 초기 iteration 시, 모델이 불안정함. anchor box는 bounding box regressor 계수를 통해 bounding box의 위치를 조정하는데, 계수는 제한 범위가 없기 때문에 anchor box는 이미지 내의 임의 지점에 위치할 수 있게 됨 --> 최적화 값 찾기 오래걸림
- 개선 : offset 예측하지 않고, grid cell에 기반해서 상대적인 location 예측 --> recall 값 5%정도 향상
- Fine-Grained Features
YOLO v2 architecture
modified YOLO는 13×13feature map에서 detection을 진행하는데 작은 object에는 효과적이지 않아, 더 앞에 있는 layer에서 26×26 크기의 feature를 가져오는 passthrough layer를 추가
--> 26×26×512 feature map을 13×13×2048 feature map으로 바꿔서 기존의 feature와 합칠 수 있음
--> 약 1%의 성능 향상
- Multi-scale training
- YOLO v2 모델을 보다 강건하게 만들기 위해 다양한 입력 이미지를 사용하여 네트워크를 학습시킴
- 10 batch마다 입력 이미지의 크기를 랜덤하게 선택하여 학습하도록 설계
- 이미지를 1/32배로 downsample시키기 때문에 입력 이미지 크기를 32배수 {320, 352, ..., 608} 중에서 선택하도록 함 (320x320 크기의 이미지가 가장 작은 입력 이미지이며, 608x608 크기의 이미지가 입력될 수 있는 가장 큰 이미지)
--> 네트워크는 다양한 크기의 이미지를 입력받을 수 있고, 속도와 정확도 사이의 trade-off를 제공
--> 입력 이미지의 크기가 작은 경우 더 높은 FPS를 가지며, 입력 이미지의 크기가 큰 경우 더 높은 mAP 값을 가지게 됨
✅ Faster
- Darknet-19 : 새로운 classification model
- VGG처럼 3×3크기의 필터를 사용, 매 pooling 단계 이후에 channel의 수를 두배로 늘림
- 3×3 conv 사이에 1×1 filter를 사용해서 feature representation을 압축
- 마지막 layer global average pooling을 사용하여 fc layer 제거 및 파라미터 수 감소
- Batch Normalization을 사용해서 학습이 안정적으로 학습되고, 빠르게 수렴되도록 함
- Training for calssification
- class 수가 1000개인 ImageNet 데이터셋을 통해 학습시킴(global average pooling 후 output 수가 1000개이므로)
--> top-1 정확도는 76.5%, top-5 정확도는 93.9% 성능
- 논문 : 224×224크리고 160 epoch 학습 후, 448×448 크기로 10 epoch 학습시켜 fine tuning
- Training for detection
Darknet-19를 detection task로 사용하기 위해 마지막 conv layer를 제거하고 1024 filter를 가진 3x3 conv layer로 대체후 1x1 conv layer를 추가
* 1x1 conv layer의 channel 수 : 예측할 때 필요한 수로, 각 grid cell마다 5개의 bounding box가 5개의 값(confidence score, x, y, w, h)과 PASCAL VOC 데이터셋을 사용하여 학습하기 때문에 20개의 class score를 예측
--> 1x1 conv layer에서 channel 수를 125(=5x(5+20))개로 지정
✅ Stronger
YOLO v2를 classification 데이터와 detection 데이터를 함께 사용하여 학습시킴으로써 보다 많은 class를 예측하는 YOLO 9000을 소개
--> classification 데이터와 detection 데이터를 섞어 학습
--> classification 데이터는 "요크셔테리어", "베들링턴테리어"와 같은 정확한 label을 가지나, detection 데이터는 "개"나 "배"와 같은 일반화된 label을 가짐
--> multi-label model 사용
- Hierarchical classification
ImageNet label로부터 계층적인 트리인 WordTree를 구성하여 classification 데이터와 detection 데이터 모두 사용 --> 모든 노드에 대해 conditional probability 계산
'Paper Review' 카테고리의 다른 글
| <NLP> [Transformer] Attention Is All You Need (2017.06) (0) | 2024.07.30 |
|---|---|
| YOLO v3 : An Incremental Improvement (0) | 2024.05.13 |
| YOLO : You Only Look Once: Unified, Real-Time Object Detection (0) | 2024.05.11 |
| Texture Synthesis Using Convolutional Neural Networks (0) | 2024.05.10 |
| A Neural Algorithm of Artistic Style (0) | 2024.05.10 |